![[자바 스터디] 멀테쓰레드 프로그래밍](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FuEWcy%2FbtrZz0AHTQ3%2FyzMT0sQkvjHxfR3Pzcq5b1%2Fimg.png)
https://github.com/whiteship/live-study/issues/10
10주차 과제: 멀티쓰레드 프로그래밍 · Issue #10 · whiteship/live-study
목표 자바의 멀티쓰레드 프로그래밍에 대해 학습하세요. 학습할 것 (필수) Thread 클래스와 Runnable 인터페이스 쓰레드의 상태 쓰레드의 우선순위 Main 쓰레드 동기화 데드락 마감일시 2021년 1월 23일
github.com
목차
- Thread 클래스와 Runnable 인터페이스
- 쓰레드의 상태
- 쓰레드의 우선순위
- Main 쓰레드
- 동기화
- 데드락
1. Thread 클래스와 Runnable 인터페이스
쓰레드를 구현하는 방법은 Thread 클래스를 상속받는 방법과 Runnable 인터페이스를 구현하는 방법이 있습니다. 두 방법 모두 run() 메서드를 구현해서 쓰레드에서 작업하고 싶은 내용을 채워야합니다.
Runnable 인터페이스 구현
public class HelloRunnable implements Runnable {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
(new Thread(new HelloRunnable())).start();
}
}
Runnable 인터페이스는 함수형 인터페이스고 run() 추상메서드 한 개만 가지고 있습니다. Runnable 인터페이스를 구현한 다음, Runnable 인스턴스를 Thread의 생성자로 넘겨줍니다.

Thread의 소스코드를 보면 이해하기 쉬울 것 같은데, 위와 같이 Thread에 target으로 Runnable 인터페이스의 구현체를 넘겨주면, Thread 인스턴스에서 run()을 실행했을 때 주입받은 Runnable 인터페이스 구현체의 run()을 실행시킬 수 있습니다.
Thread 클래스를 상속
public class HelloThread extends Thread {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
(new HelloThread()).start();
}
}
Runnable 구현체를 주입받지 않으면, 즉 target이 없으면 그냥 Thread를 상속받고 run()을 오버라이드해도 됩니다. 두 방법으로 Thread를 생성할 수 있지만, Runnable 인터페이스를 구현하는 것이 일반적이라고 합니다. 왜냐하면 Thread 클래스를 상속받으면 다른 클래스를 상속받을 수 없고, Runnable 인터페이스를 구현하는 것이 더 재사용성이 높고 객체지향적인 방법이기 때문입니다.
start()와 run()
추상메서드 run()을 구현했는데 왜 실행하려고보니 start()메서드를 사용하는 것일까요?
모든 쓰레드는 독립적인 호출스택을 갖습니다. 단순하게 run()을 실행하면 새로운 쓰레드를 생성하는 것이 아니라, 즉 새로운 호출스택을 만드는 것이 아니라 main의 호출스택 위에 run()메서드를 올리게 되는 것뿐입니다. 하지만 start()를 실행하면 새로운 쓰레드를 위한 호출스택을 생성하고 생성된 호출스택 위에 run()이 첫 번째로 올라가게 됩니다.
run() 메서드 실행시 호출스택

start() 메서드 실행시 호출스택

자바의 정석에 있는 예제 코드로 확인해보겠습니다. 고의로 예외를 발생시켜서 호출스택을 출력할 것입니다.
class MyThread extends Thread {
public void run() {
throwException();
}
public void throwException() {
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
}
위와 같이 예외를 발생시키는 쓰레드를 작성하고
public class ThreadEx {
public static void main(String[] args) throws Exception {
MyThread t1 = new MyThread();
t1.run();
}
}
myThread를 생성한 후 run() 메서드를 실행시킵니다.

예상한 바와 같이 MyThread를 위한 호출스택이 생성되지 않고 run()이 main() 위에 추가된 것을 확인할 수 있습니다.
public class ThreadEx {
public static void main(String[] args) throws Exception {
MyThread t1 = new MyThread();
t1.start();
}
}
하지만 위처럼 start()를 실행시키면

호출스택의 첫 메서드가 run()이고 main() 메서드가 포함되어 있지 않은 것을 확인할 수 있습니다.
싱글쓰레드와 멀티쓰레드
https://www.youtube.com/watch?v=jSaBkvtHhrM
"스레드를 많이 쓸수록 항상 성능이 좋아질까요?"라는 질문인데, 영상에서는 CPU 바운드잡과 I/O 바운드잡으로 나눠서 설명합니다. CPU 바운드 잡의 경우 코어 수와 비슷한 수준 이상으로 스레드 수를 늘려봤자 크게 이점이 없다고 합니다. 오히려 코어에서 경합하는 스레드가 많아질수록 context switching에 의한 오버헤드로 성능이 안 좋아질 수도 있다고 합니다.
하지만 I/O 바운드에서는 I/O 작업이 길어서 CPU가 놀고 있는 시간이 길기 때문에 쓰레드를 늘리는 것이 오버헤드를 감안해도 성능이 더 좋아질 수 있다고 합니다.
자바의 정석에 I/O 작업을 처리할 때 멀티쓰레딩이 유리해지는 예시를 소개하겠습니다.
public class ThreadEx6 {
public static void main(String[] args) {
String input = JOptionPane.showInputDialog("아무값이나 입력하세요.");
System.out.println("입력하신 값은 " + input + "입니다.");
for (int i=10; i>0; i--) {
System.out.println(i);
try {
Thread.sleep(1000);
} catch (Exception e) {}
}
}
}
하나의 쓰레드에서 두가지 태스크를 수행합니다. 하나는 사용자에게 값을 입력받고 출력하는 것이고, 또 하나는 10부터 1까지 순차적으로 값을 출력하는 것입니다.
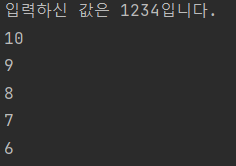
만약 사용자에게 입력 받는 시간이 무한히 길어지면, 두번째 작업도 무한히 길어지고 CPU가 의미없이 놀고 있는 시간이 길어집니다.
public class ThreadEx7 {
public static void main(String[] args) {
ThreadEx7_1 th1 = new ThreadEx7_1();
th1.start();
String input = JOptionPane.showInputDialog("아무값이나 입력하세요.");
System.out.println("입력하신 값은 " + input + "입니다.");
}
}
class ThreadEx7_1 extends Thread {
public void run() {
for (int i=10; i>0; i--) {
System.out.println(i);
try {
sleep(1000);
} catch(Exception e) {}
}
}
}
하지만 위와 같이, 10부터 1까지 출력하는 일을 다른 쓰레드에게 맡기고 사용자에게 값을 입력받고 출력하는 작업과 동시에 실행하면, 사용자에게 값을 입력받을 때까지 CPU가 노는 것이 아니라 사용자 입력을 기다리면서 10부터 1까지 출력하는 작업을 맡길 수 있습니다.

2. 쓰레드의 상태
쓰레드의 상태
| NEW | 쓰레드가 생성되고 start()가 호출되지 않은 상태 |
| RUNNABLE | 실행 중 또는 실행 가능한 상태 |
| BLOCKED | 동기화블럭에 의해 일시정지된 상태 |
| WAITING | 쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은 일시적인 상태 |
| TERMINATED | 쓰레드의 작업이 종료된 상태 |
쓰레드의 실행제어 메서드
| static void sleep(long millis) static void sleep(long millis, int nanos) |
지정된 시간 동안 쓰레드를 일시정지시킨다. (WAITING상태가 된다.) 지정한 시간이 지나고 나면, 자동적으로 다시 RUNNABLE 상태가 된다. |
| void join() void join(long millis) void join(long millis, int nanos) |
지정된 시간동안 쓰레드가 실행되도록 한다. 지정한 쓰레드가 전부 실행되기 전까지 호출한 쓰레드는 WAITING 상태가 된다. 작업이 종료되면 다시 RUNNABLE상태가 된다. |
| void interrupt() | sleep() 혹은 join()에 의해 WAITING 상태인 쓰레드를 다시 RUNNABLE 상태로 만든다. 해당 쓰레드에서는 InterruptedException이 발생한다. |
| void stop() | 쓰레드를 종료시킨다. 즉 TERMINATED 상태로 만든다. |
| void suspend() | 쓰레드를 일시정지시킨다. resume()을 실행하면 다시 RUNNABLE 상태가 된다. |
| void resume() | suspend()에 의해 일시정지된 쓰레드를 실행대기상태로 만든다. |
| static void yield() | 실행 중에 자신에게 주어진 실행시간을 다른 쓰레드에 양보하고 실행대기 상태가 된다. |
sleep
public class SleepMessages {
public static void main(String[] args) {
String importantInfo[] = {
"Mares eat oats",
"Does eat oats",
"Little lambs eat ivy",
"A kid will eat ivy too"
};
for (int i=0; i< importantInfo.length;i++) {
try {
Thread.sleep(4000);
} catch(InterruptedException e) {
return;
}
System.out.println(importantInfo[i]);
}
}
}
sleep()을 사용하면 일정 시간동안 쓰레드의 실행을 멈출 수 있습니다. 그리고 출력결과로 4초에 한번 씩 importantInfo의 문자열이 순서대로 출력됩니다. 주의할 점은 sleep()은 지정된 시간이 끝날 때 뿐만 아니라 interrupt()가 호출되어 InterruptedException이 발생해도 잠에서 깨어나 실행대기 상태가 될 수 있기 때문에 항상 위처럼 try-catch문으로 예외처리를 해주거나, 위 예제 코드의 경우 try-catch문을 사용하지 않는다면 main method에 throws InterruptedException를 추가해야한다는 것입니다.
그리고 sleep은 static 메서드입니다. 그래서 만약 main쓰레드에서 th1 쓰레드를 생성하고 th1.sleep()을 사용해봤자 th1가 대기하지 않습니다. 앞의 참조변수가 무엇이던 실제로 영향받는 것은 main쓰레드기 때문에 의도와는 다르게 main쓰레드가 실행대기 상태가 됩니다. th1을 대기시키고 싶으면 th1 쓰레드 내부에서 Thread.sleep()을 사용해야 합니다.
3. 쓰레드의 우선순위
Thread는 우선순위라는 멤버 메서드를 가지고 있습니다. 쓰레드별로 우선순위를 다르게 해서 높은 우선순위에 있는 쓰레드가 더 많은 작업시간을 얻을 수 있습니다.

위처럼 쓰레드 우선순위의 범위는 1부터 10까지이고, 우선순위를 setPriority로 지정하지 않으면 기본적으로 5입니다. 쓰레드의 우선순위는 쓰레드를 생성한 쓰레드로부터 상속받는데, main메서드는 우선순위가 5이므로 main에서 생성하는 쓰레드도 기본적으로 5가 되는 것입니다.
4. Main 쓰레드
main 쓰레드는 JVM이 가장 먼저 실행시키는 쓰레드입니다. 프로그램을 실행하면 main 쓰레드를 먼저 생성한 후 main 메서드를 호출해서 작업을 수행합니다. 그리고 main 메서드에서 생성한 쓰레드가 있다면 위에서 설명한 것처럼 각 쓰레드 별로 호출스택을 따로 생성하고 동시에 멀티쓰레드 프로그램을 실행하는 것입니다.
5. 동기화
서로 다른 쓰레드가 공유 데이터에 동시에 접근하면 예상치 못한 문제가 생길 수 있습니다.
public class SynchEx1 {
static class Counter {
public static int count = 0;
public static void increment() {
count++;
}
static class MyRunnable implements Runnable {
@Override
public void run() {
for (int i=0; i<10000;i++) {
Counter.increment();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[5];
for (int i=0; i<threads.length;i++) {
threads[i] = new Thread(new MyRunnable());
threads[i].start();
}
for (int i=0; i<threads.length; i++) {
threads[i].join();
}
System.out.println("count = " + count);
}
}
}
위 예제는 Counter 클래스의 공유변수 count에 5개의 쓰레드가 동시에 접근해서 값을 늘려주는 예제입니다. 쓰레드가 5개 생성됐고, 5개의 쓰레드가 각각 increment()를 만번씩 호출합니다. 그래서 5개 쓰레드가 모두 종료돼서 count를 출력하면 50000이 출력될 것으로 예상할 수 있는데, 사실 실행시켜보면 21745, 15747, .. 실행할 때마다 예상치 못한 다른 값이 출력됩니다.
count++;은 한줄짜리 코드지만 더 로우레벨에서는 3단계로 이뤄집니다. 1. 저장된 count값을 레지스터에 저장한다. 2. 레지스터의 값을 1 증가시킨다. 3. 다시 count에 값을 복사한다.
그래서 만약 어떤 쓰레드 A가 2번 과정을 실행해서, 즉 레지스터의 값을 100으로 증가시킨 후 대기 상태가 됐다고 가정합시다. 다른 쓰레드들이 열심히 값을 바꿔서 count를 200번 증가시켜도, 대기 상태가 된 쓰레드 A가 다시 실행돼서 3번 과정부터 다시 실행하면, count가 200번 증가된 것은 전부 무시되고, 당시 저장했던 값 100을 count에 저장하게 됩니다.
그래서 공유데이터에 접근할 때는 한 쓰레드가 작업을 끝날 때까지 다른 쓰레드가 방해하지 못하게 하는 것이 중요합니다. 임계영역과 lock이라는 개념을 사용하는데, 공유 데이터에 접근하는 코드를 임계영역으로 지정하고, 임계영역에 들어가는 쓰레드는 lock을 가진 하나의 쓰레드로 제한합니다. 이렇게 순서를 정해둬서 공유데이터에 동시에 접근하지 못하게 하는 것을 동기화, Synchronization이라고 합니다.
synchronized
자바에서는 synchronized라는 키워드를 제공하는데, synchronized를 붙인 메서드는 메서드 전체가 임계영역으로 지정됩니다. 그래서 위 예제에서 increment() 앞에 synchronized를 붙이면, increment()를 실행한 쓰레드가 Counter의 락을 얻어서, 다른 쓰레드가 임계영역의 코드를 실행하는 것을 제한할 수 있습니다.
synchronized public static void increment() {
count++;
}
위처럼 synchronized를 붙이고 위 예제를 실행하면 예상한 결과값 50000을 얻을 수 있습니다.
Counter 클래스에 increment() 뿐만 아니라 counter의 값을 줄이는 decrement()도 추가합니다. decrement() 또한 synchronized 키워드를 붙이면, 어떤 쓰레드가 increment()를 실행중일 때 다른 쓰레드는 increment() 뿐만 아니라 decrement()도 실행할 수 없습니다. 어떤 쓰레드가 객체의 락을 얻으면 다른 쓰레드는 그 객체의 synchronized가 붙은 모든 메서드를 실행할 수 없습니다.
public class SynchEx1 {
static class Counter {
public static int count = 0;
synchronized public static void increment() {
count++;
}
synchronized public static void decrement() {
count--;
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i=0; i<10000; i++) {
Counter.increment();
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
Counter.decrement();
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
}
그래서 위처럼 두 쓰레드가 하나는 counter의 값을 늘리고자 하고, 하나는 counter의 값을 줄이고자 하면, 예상한 바와 같이 count의 출력값으로 0을 얻을 수 있습니다.
6. 데드락
데드락은 두 개 이상의 쓰레드가 lock을 쥔 상태로 block 상태이고 다른 쓰레드가 lock을 반환하기 기다리는데, 다른 쓰레드 또한 마찬가지로 lock을 쥔 상태로 block 상태가 돼서 서로 무한정 대기하는 상태를 말합니다.
public class Deadlock {
static class Friend {
private final String name;
public Friend(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
public synchronized void bow(Friend bower) {
System.out.format("%s: %s"
+ " has bowed to me!%n",
this.name, bower.getName());
bower.bowBack(this);
}
public synchronized void bowBack(Friend bower) {
System.out.format("%s: %s"
+ " has bowed back to me!%n",
this.name, bower.getName());
}
}
public static void main(String[] args) {
final Friend alphonse =
new Friend("Alphonse");
final Friend gaston =
new Friend("Gaston");
new Thread(new Runnable() {
public void run() { alphonse.bow(gaston); }
}).start();
new Thread(new Runnable() {
public void run() { gaston.bow(alphonse); }
}).start();
}
}실행결과입니다.
Alphonse: Gaston has bowed to me!
Gaston: Alphonse has bowed to me!
bow 메서드는 다른 Friend 객체 friend를 받아서 자신의 이름과 friend의 이름을 반환합니다. 그리고 friend가 bowBack 메서드를 호출합니다.
첫번째로 alphonse가 gaston에게 인사합니다. 그리고 gaston도 alphonse에게 인사합니다. bow는 synchronize 키워드가 붙어있기 때문에 첫번째 쓰레드에서 alphonse의 락을 쥔 상태이고 두번째 쓰레드에서 gaston의 락을 쥔 상태입니다. 첫번째 쓰레드에서 alphonse가 gaston에게 인사한 뒤, gaston이 bowBack해야하는데, gaston의 락은 두번째 쓰레드가 가지고 있습니다. 두번쨰 쓰레드도 마찬가지로 gaston이 인사하고 alphonse가 bowBack을 실행해야하는데, alphonse의 락은 첫번째 쓰레드가 가지고 있기 때문에, 두 쓰레드가 서로가 락을 쥐고 블락상태에서 상대방의 락을 기다리고 있는 상황입니다.
'자바 > 백기선 자바스터디' 카테고리의 다른 글
| [백기선 자바스터디] 람다식 (0) | 2022.12.30 |
|---|---|
| [백기선 자바스터디] 제네릭 (0) | 2022.10.19 |
| [백기선 자바스터디] enum (0) | 2022.10.10 |
| [백기선 자바스터디] 예외 처리 (0) | 2022.09.21 |
| [백기선 자바스터디] 인터페이스 (0) | 2022.08.10 |