![[OS] CPU scheduling](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FEkRtf%2FbtrV5fnmXmt%2FNjQk8O7ej1jvnXwddr5FYk%2Fimg.png)
Operating System Concepths, 10th edition을 학습하고 정리한 내용입니다.
CPU scheduling 기본 개념
CPU 스케쥴링이 왜 필요한지, 구체적으로 어떤 알고리즘이 있는지 알아보겠습니다.
CPU - I/O burst cycle
CPU만 사용하는 일련의 단계를 CPU 버스트라 하고 I/O 작업을 실행하는 일련의 단계를 I/O 버스트라고 합니다. 프로그램은 CPU 버스트와 I/O 버스트를 번갈아가며 실행합니다. 그런데 어떤 프로그램은 사람과 인터렉션이 빈번하게 일어나서 파일을 읽고 쓰는 시간이 길어 I/O 버스트가 메인이 될수도 있고, 어떤 프로그램은 CPU만 쭉 사용해서 연산을 쉬지 않는 경우도 있습니다. 즉 프로그램은 CPU 버스트와 IO 버스트의 반복이지만 프로그램마다 그 빈도와 길이가 다릅니다.

위 그래프는 CPU 버스트가 짧은 프로세스부터 긴 프로세스까지 빈도의 분포를 보여주는 그래프이입니다. 빈도를 확인해보니 CPU 버스트가 짧은 프로세스 즉 중간에 I/O작업을 수행하는 경우가 많고 CPU만 길게 사용하는 경우는 빈도가 굉장히 낮아보입니다. CPU를 짧게 쓰고 I/O 작업이 빈번하게 일어나는 프로그램을 I/O 바운드 잡이라고 부르고 반면 CPU만을 오랫동안 사용하는 프로그램을 CPU 바운드 잡이라고 부릅니다.
CPU Scheduler
어떤 프로세스를 ready 큐에서 꺼내서 메모리에 올릴지 정합니다. CPU 스케쥴러라는 별도의 하드웨어가 있는 것은 아니고 운영체제 안에서 스케쥴링하는 코드를 말합니다.
CPU Dispatcher
CPU의 제어권을 실제로 CPU 스케쥴러에 의해 선택된 프로세스에게 넘기는 역할을 합니다. 마찬가지로 어떤 하드웨어가 아니라 특정 기능이고, CPU를 넘겨주는 역할을 하는 커널코드입니다.
Preemptive and Nonpreemptive Scheduling
크게 두가지로 나눌 수 있습니다.
- Preemptive : CPU를 강제로 빼앗을 수 있습니다. 선점형이라고 부릅니다.
- Non Preemptive : 프로세스가 자진해서 CPU를 반납하는 경우입니다. CPU를 일단 얻으면 필요할 때까지 사용하는 것을 보장해주는 방법입니다. 비선점형입니다.
아래와 같이 네 가지 상황을 예시로 들 수 있습니다.
- 프로세스가 running 상태에서 waiting 상태로 전환 : I/O를 요청하는 시스템콜을 예시로 들 수 있습니다. I/O 작업이 오래 걸리기 때문에 CPU를 자진해서 내놓는 것입니다. 즉 Non Preemptive한 상태 변화입니다.
- 프로세스가 running 상태에서 ready 상태로 전환 (interrupt) : 타이머 인터럽트를 예시로 들 수 있습니다. 마찬가지로 작업이 남아도 무한정 CPU를 사용할 수는 없기 때문에 강제로 CPU를 뺴앗습니다. 즉 Preemptive한 상태 변화입니다.
- 프로세스가 waiting 상태에서 ready 상태로 전환 : I/O 요청이 끝나면 디바이스 컨트롤러가 인터럽트를 걸어서 레디로 바꾸고 CPU를 얻을 수 있는 권한을 얻게 됩니다. Preemptive한 상태 변화입니다.
- 프로세스가 종료됨 terminate : 자진해서 반납하기 때문에 Non Preemptive입니다.
Scheduling Criteria
프로세스 스케쥴링의 알고리즘을 선택하는 기준에 대해 알아보겠습니다.
시스템 입장에서의 성능척도입니다.
- CPU utilization : 전체 시간에서 CPU가 놀지 않고 일한 시간의 비율입니다. CPU 사용시간을 최대화하기 위함입니다.
- Throughput : 단위 시간당 완료되는 프로세스의 수입니다. 주어진 CPU를 가지고 가능한 많은 작업을 처리하기 위함입니다.
프로세스 입장에서 성능척도입니다. 즉 고객과 관련해서 기다리는 시간, 처리되는 시간을 포함합니다.
- Turnaround time : 프로세스가 처리되는데 걸리는 시간. waiting 큐, ready 큐에서 대기하는 시간과, 실행시간, I/O 리퀘스트를 처리하는 시간 모두를 포함합니다.
- Response time : 프로세스가 시작되기까지 대기하는 시간. waiting 큐, ready큐에 있던 시간의 합입니다.
Scheduling Algorithms
FCFS (first-come, first-served)
- ready 큐에 먼저 들어온 프로세스가 먼저 실행됩니다.
- FIFO 큐를 이용해서 쉽게 구현할 수 있습니다.
- non preemptive합니다. 일단 CPU를 얻으면 자발적으로 종료하거나 I/O 요청이 오기전까지 계속 실행할 수 있습니다.
- Convoy effect라고 해서 들어온 순서대로 실행하기 때문에 긴 프로세스가 먼저 도착하면 짧은 프로세스의 대기 시간이 길어지는 단점이 있습니다.
| case1 | case2 | ||
| Process | Burst Time | Process | Burst Time |
| 1 | 24 | 1 | 3 |
| 2 | 3 | 2 | 3 |
| 3 | 3 | 3 | 24 |
case 1
Total waiting time : 0 + 24 + 27 = 51
Total turnaround time : 24 + 27 + 30 = 81
case 2
Total waiting time : 0 + 3 + 6 = 9
Total turnaround time : 3 + 6 + 30 = 39
Convoy Effects
FCFS의 경우 case2처럼 더 효율적인 경우가 있는데도 들어온 순서대로 처리하기 때문에, CPU 사용시간이 긴 프로세스 때문에 사용시간이 짧은 프로세스가 오래 기다리는 현상이 일어납니다. 이를 convy effects라고 합니다.
SJF (Shortest-Job-First Scheduling)
- CPU burst가 가장 짧은 프로세스를 먼저 실행합니다.
- 위 FCFS 예시와 다르게 프로세스가 몇번째 들어오던 case2처럼 스케쥴링할 것입니다.
- 이상적으로 waiting time을 가장 최소화할 수 있는 알고리즘입니다.
- 하지만 다음 프로세스의 CPU 버스트를 예상할 수 없어서, 프로세스의 이전 CPU 버스트를 이용해서 다음 CPU 버스트를 예상합니다.
- preemptive 혹은 nonpreemptive하게 설계할 수 있다.
$\tau_{n+1} = \alpha t_{n} + (1 - \alpha) \tau_{n}$
$\tau_{n+1}$ : 예상되는 다음 CPU burst
$t_{n}$ : 가장 최근 CPU burst (바로 이전)
$\tau_{n}$ : 바로 이전 예상된 CPU burst (history의 종합)
$\alpha$ : $t_{n}$의 가중치로 1이면 이전 history를 전혀 고려하지 않게 됩니다.

SJF는 두가지 문제점이 있습니다. 첫번쨰는 Starvation입니다. SJF는 극단적으로 CPU를 짧게 사용하는 프로세스를 선호합니다. 따라서 길게 사용하는 프로세스의 대기 시간이 무한히 길어질 수도 있습니다. 또 다른 점은 다음 프로세스의 CPU 사용 시간이 예측한 값이기 때문에 정확하게 추정하기 힘들다는 점입니다.
SRTF ( shortest-remaining-time-first scheduling)
- 선점형 SJF, remaining time을 기준으로 프로세스를 결정합니다. 만약 레디큐 안에 실행중인 프로세스의 남은 시간보다 더 남은 시간이 적은 프로세스가 있으면 레디큐로 보낼 수 있습니다.
preemptive type vs nonpreemptive 비교
| Process | Arrival Time | Burst Time |
| 1 | 0 | 8 |
| 2 | 1 | 4 |
| 3 | 2 | 9 |
| 4 | 3 | 5 |
1. preemptive type
0초 : $P_{1}$가 실행된다.
1초 : $P_{1}$이 레디큐에 들어가고 $P_{2}$가 실행된다.
5초 : $P_{2}$가 종료되고 $P_{4}$, $P_{1}$, $P_{3}$ 순서대로 실행된다.

Total waiting time : (10-1) + (1-1) + (17-2) + (5-3) = 26
Average waiting time : 26/4 = 6.5
2. nonpreemptive type

Total waiting time : (0-0) + (8-1) + (12-2) + (17-3) = 31
Average waiting time : 31/4 = 7.5
preemptive한 SRTF보다 nonpreemptive하게 설계한 SFJ의 평균 대기 시간이 짧은 것을 확인할 수 있습니다.
RR (Round Robin)
- 현대적으로 사용하는 스케쥴링은 라운드로빈에 기반합니다.
- preemptive한 FCFS라고 생각할 수 있습니다. 할당된 시간이 지나면 CPU를 뻇습니다.
- time quantum 단위로 실행된다. 보통 10에서 100ms입니다.
- time quantum이 늘어날수록 FCFS에 가까워집니다.
- 실행 시간이 남으면 레디큐에 들어갑니다.
- 레디큐는 circular queue입니다.
| case1 | case2 | ||
| Process | Burst Time | Process | Burst Time |
| 1 | 24 | 1 | 3 |
| 2 | 3 | 2 | 3 |
| 3 | 3 | 3 | 24 |
- CPU 버스트가 time quantum보다 작으면 자발적으로 종료되고 다음 프로세스가 실행됩니다.
- CPU 버스트가 time quantum보다 크면 컨텍스트 스위칭이 발생해서 레디큐의 tail로 들어갑니다.
- 위와 같은 특징 때문에 CPU를 길게 사용하는 프로세스는 대기하는 시간이 길어지고 짧게 사용하는 프로세스는 대기 시간이 짧아집니다. 즉 대기 시간이 실행시간에 비례하게 됩니다.
- 가장 큰 장점은 응답시간이 빨라진다는 점입니다.
case1
time quantum = 4s
0초 : $P_{1}$이 4초까지 실행되고 레디큐로 들어간다.
4초 : $P_{2}$이 7초까지 실행되고 종료된다.
7초 : $P_{3}$이 10초까지 실행되고 종료한다.
10초 : $P_{4}$이 실행된다.
Total waiting time : (10-4) + 4 + 7 = 17
Average waiting time : 17/3 = 5.66
FCFS의 case1에서 waiting time이 51초였던 것에 비해 34초 빠르다.
하지만 time quantum을 사용하고 크기를 줄인다고 항상 성능이 좋아지는 것은 아닙니다. 예를 들어 CPU 버스트가 10초인 프로세스가 3개가 주어지면, 만약 time quantum이 1초면 평균 turnaround time이 29초이고, time quantum이 10초면 평균 turnaround time이 20초로 감소합니다. 따라서 time quantum을 적절하게 정하는 것이 중요하고, 보통 알려지기를 time quantum이 CPU burst의 80퍼센트 이상으로 설정하면 된다고 합니다.
또한 time quantum이 너무 짧아지면 컨텍스트 스위칭이 그만큼 더 빈번하게 일어나고 오버헤드가 커집니다. 때문에 CPU 사용시간 예측이 힘든 경우에 사용하면 좋습니다.
Priority-based
- 우선순위를 바탕으로 프로세스를 결정합니다.
- 우선순위가 같으면 FCFS와 같습니다.
- SJF는 Priority 스케쥴링의 특수한 경우로 priority는 다음 프로세스의 CPU 버스트의 역수입니다.
- starvation(indefinite blocking) : 낮은 우선순위의 프로세스가 실행되지 못할 수도 있습니다.
- aging : starvation을 해결하는 방법 중 하나로 대기를 오래할수록 우선순위를 높이는 방법입니다.
MLQ (Multilevel Queue Scheduling)
이전의 레디큐는 프로세스들이 한줄로 대기하고 있었는데, 이후 소개되는 multilevel queue를 사용하면 여러 줄의 큐로 대기할 수 있습니다. Priority와 라운드 로빈 스케쥴링을 함께 사용하면, 모두 같은 큐에서 대기하기 때문에, 가장 우선순위가 높은 프로세스를 찾을 때 O(n)의 시간복잡도가 필요합니다. 그래서 실제로는 우선순위마다 큐를 분리하는 것이 유용할 때가 있습니다. multilevel queue를 사용해서 큐마다 우선순위를 부여해서 우선순위가 높은 큐부터 실행하는 것입니다. 같은 큐에 있는 프로세스들은 우선순위가 같기 때문에 그 때는 라운드로빈으로 순서가 정해집니다.
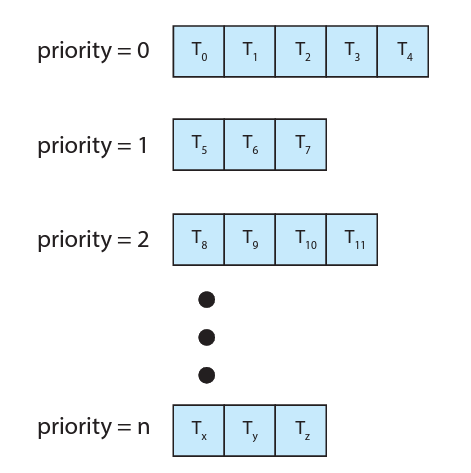
예를 들어 안드로이드의 경우 게임과 관련된 프로세스(네트워크, 디스플레이, 사운드 등)가 낮은 우선순위에 있고 전화와 관련된 프로세스가 높은 우선순위에 있을 수 있습니다. 그래서 전화가 없을 때는 낮은 우선순위에 있는 큐에 라운드로빈 스케쥴링을 하다가 전화가 오면 인터럽트되고 전화벨이 울리는 프로세스가 실행되는 것입니다.
또 다른 예로 들면 다음 순서와 같이 우선순위를 나눠서 multilevel queue를 만들 수 있습니다.
- Real-time processes
- System processes
- Interactive processes
- Batch processes
MLFQ (Multilevel Feedback Queue Scheduling)
프로세스의 대기 큐를 바꿀 수 있는 큐입니다. 일반적으로 MLQ 스케쥴링은 프로세스가 큐에 들어가면 우선순위가 영원히 바뀌지 않습니다. 그래서 우선순위가 낮은 프로세스는 대기시간이 너무 길어지는 단점이 있는데, MLFQ를 사용해서 프로세스가 큐를 이동하는 것으로 해결할 수 있습니다. CPU를 너무 많이 사용했으면 낮은 우선순위 큐로 보내거나 혹은 대기시간이 너무 긴 낮은 우선순위에 있는 프로세스를 높은 우선순위의 큐로 보내서 starvation을 방지하는 식으로 설계할 수 있습니다.
알고리즘 예시
예를 들어 아래와 같이 3개의 우선 순위 큐를 갖는다고 합시다. 모든 프로세스는 처음에는 time quantum이 8ms인 0번 우선순위큐로 들어갑니다. 0번 큐에 프로세스가 없어야 1번큐 (quantum = 16ms)가 실행될 수 있고, 1번큐가 없어야 2번큐(FCFS)가 실행될 수 있습니다. 이렇게 설계하면 8ms 이하의 짧은 버스트를 가지는 프로세스가 금방금방 처리돼서 대기시간을 줄일 수 있고, 버스트가 긴 프로세스는 낮은 우선순위의 큐로 이동시킬 수 있습니다. 대신 우선순위가 낮을수록 실행될 기회가 적으니 quantum을 점점 늘려서 차례가 오면 프로세스를 끝내버리는 것입니다.
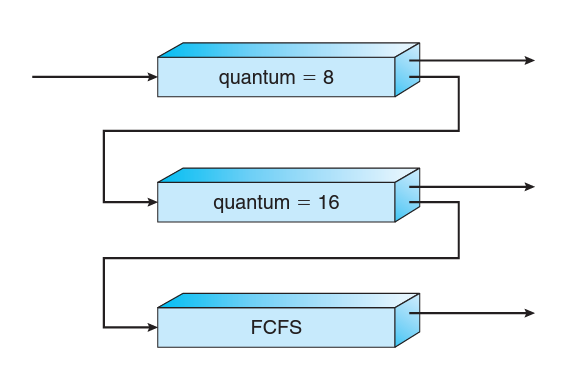
MLFQ 스케쥴러는 아래 파라미터로 정의할 수 있습니다.
- 큐의 개수
- 각 큐에 적용할 스케쥴링 알고리즘
- 높은 우선순위의 큐로 어떻게 보낼지
- 낮은 우선순위의 큐로 어떻게 보낼지
- 어떤 큐로 프로세스를 보낼지
'CS > 운영체제' 카테고리의 다른 글
| [OS] 인터럽트, 시스템 콜, 커널모드, 사용자모드 (0) | 2023.02.03 |
|---|---|
| [OS] 뮤텍스, 세마포어, 모니터 (0) | 2023.01.18 |
| [OS] 동기화 문제, Peterson's solution, 하드웨어 명령어 (0) | 2023.01.15 |
| [OS] Threads & Concurrency (0) | 2023.01.11 |
| [OS] 프로세스 : 프로세스 개념, 컨텍스트 스위칭, 생성 및 통신 (0) | 2023.01.08 |