![[자료구조] 자바 연결 리스트 소개 및 구현](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcxeOC4%2FbtrSPPMj8zW%2FAAAAAAAAAAAAAAAAAAAAACKqLe7gI_-RMMmBJBPPHRUE228LHAc2PTYZJrsGS4AC%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DpWSbTLhjcJLT804oarwGkFBhr0g%253D)
https://www.youtube.com/playlist?list=PLpPXw4zFa0uKKhaSz87IowJnOTzh9tiBk
Data Structures
Rob teaches CS310, Data Structures in Java at San Diego State University. These lectures accompany that course. There are both discussions of the topics and ...
www.youtube.com
Rob Edwards 교수님의 CS310 Data Structures in Java를 공부하고 정리한 내용입니다.
부스트 코스 자바로 구현하고 배우는 자료구조에서도 학습할 수 있습니다.
연결리스트를 간단히 소개하고 구현합니다. addFirst, addLast로 노드를 더하고 removeFirst, removeLast 노드를 삭제하는 등 메서드를 여러 boundary condition을 고려해서 구현하고 시간 복잡도 측면에서 어떤 장단점이 있는지 소개합니다.
1-1. 연결 리스트 소개
Array는 사이즈를 관리하기 어렵다는 문제점이 있다. 요소가 너무 적으면 여분의 메모리 공간이 낭비되고, 너무 많으면 새로 값을 추가할 때마다 array를 다시 만들어야한다.
이번 장에서 소개할 Linked List는 항상 정확한 크기를 갖도록 설계돼 있어서, 위에서 언급한 Array의 문제점이 없다. Sequential data 혹은 많은 양의 데이터를 다룰 때 주로 사용한다.

연결 리스트는 위처럼 여러 노드를 포인터로 연결하는 자료구조이다. 각 노드는 다음 노드를 가르키는 next 포인터와 데이터를 가르키는 포인터가 있다. 노드 D에서는 다음 노드가 없기 때문에 next가 null을 가리킨다.
연결 리스트는 head라는 노드로 시작한다. head는 항상 리스트의 첫 요소를 가리킨다. 우리는 head의 노드밖에 접근할 수 없기 때문에 B, C, D를 부를 때 head를 통해 A를 부르고 head.next를 통해 B를 부르는 방식으로 찾고자하는 값을 탐색한다.
하지만 노드가 너무 많아지면 head.next.next.next를 끝없이 사용할 수 없기 때문에, 임시 포인터를 만들어서 탐색하는 방식을 사용하는데, 다음장부터 구체적으로 어떻게 연결 리스트를 구현하는 방법을 소개한다.
1-2. 노드의 크기
첫 번째로 LinkedList를 정의한다. 그리고 LinkedList 내부에 inner class인 노드를 정의한다.
public class LinkedList<E> implements ListI<E> {
class Node<E> {
E data;
Node<E> next;
public Node(E obj) {
data = obj;
next = null;
}
}
private Node<E> head;
private int currentSize;
public LinkedList() {
head = null;
currentSize = 0;
}
}
inner class이기 때문에 LinkedList의 외부에서 node에 접근할 수 없다. next가 inner class에 있지 않으면 외부에서 next의 값을 바꿀 수 있고 Node의 위치를 잃어버리게 된다.
LinkedList에 currentSize가 정의돼있는데, 크기를 알고 싶을때마다 노드 갯수를 계산하면 크기에 비례해서 O(n)의 복잡도를 갖는다. 그래서 currentSize를 변수로 갖고, 노드를 추가할 때마다 currentSize를 갱신해주면, 크기를 원할 때마다 계산하는게 아니라 O(1)의 complexity로 LinkedList의 크기를 구할 수 있다.
1-3. 경계조건
앞으로 어떤 자료구조를 만들던 5가지 Boundary Condition을 고려해야한다.
- Empty data structure : remove할 때 어떻게 처리해줘야하는지?
- Single element in the data structure : remove한다면 Empty data structure가 된다.
- Adding/Removing beginning of data structure : 첫 요소에 더하거나, 제거해줄 때 어떤 문제가 있을지 고려한다. 헤드는 어떻게 다룰지 고려한다.
- Adding/Removing end of the data structure : 연결리스트에서 complexity를 줄이기 위해 여러 방법을 배울 것
- Working in the middle
1-4. addFirst 메소드

첫번째 요소를 추가하고 싶으면 위 그림처럼 head의 포인터를 새로운 노드를 가리키게 하면 된다.
public void addFirst(E obj) {
Node<E> node = new Node<E>(obj);
node.next = head;
head = node;
currentSize;
}
위의 노드가 기존 첫번째 요소를 가리키고, head를 새로운 노드에 가리키도록 순서를 지키는 것이 중요하다. 그림으로 나타내면 다음과 같다.

경계조건은 고려할 필요 없다. 리스트가 비어있으면 head가 null을 가리킬 것이고 새로운 노드도 head가 가리키는 null을 가리키면 된다. 그리고 head가 null이 아닌 새로운 node를 가리키면 된다. 새로운 요소를 추가하는 과정에서 뒷부분을 고려할 필요가 없기 때문에 시간 복잡도 또한 1이다.
1-5. addLast 메소드
위에서 언급했듯이 마지막 노드에 접근할 때 head.next.next.next를 끝없이 사용하는 방법은 사용하지 않는다.
마지막 노드를 가리키도록 임시포인터를 이용한다.

head 부터 시작해서 null을 가리키는 노드를 찾는다. 코드로 구현하면 다음과 같다.
public void addLast (E obj) {
Node<E> node = new Node<E>(obj);
if (head == null) {
head = node;
currentSize++;
return
}
Node<E> tmp = head;
while (tmp.next != null)
tmp = tmp.next;
tmp.next = node;
}
Boundary Condition
리스트가 empty이면 tmp.next가 null이기 때문에 NullPointerException이 일어나므로 예외처리한다. List가 empty라서 head가 null을 가리키면 head를 새로운 노드로 지정해주고 currentSize를 늘려서 요소가 하나인 List로 만들어주면 된다.
tail 포인터 사용, 시간복잡도
while문에서 null을 확인하는 과정의 시간복잡도는 O(n)이다. 그런데 만약 tail 포인터를 만들어서 tail이 항상 마지막 요소를 가리키게 하면 마지막 요소를 빠르게 찾을 수 있다.
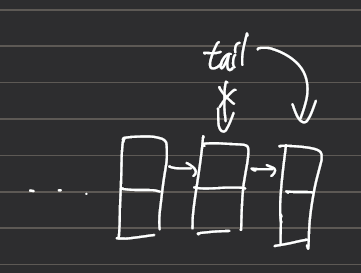
새로운 요소를 추가할 때 tail이 기존의 마지막 요소가 아닌 새로운 노드를 가리키게하면 된다.
public void addLast (E obj) {
Node<E> node = new Node<E>(obj);
if (head == null) {
head = tail = node;
currentSize++;
return;
}
tail.next = node;
tail = node;
currentSize++;
return;
}
tail을 사용하기 전의 시간복잡도는 O(n)이지만, tail을 사용하고 시간복잡도를 O(1)로 줄일 수 있다.
1-6. removeFirst 메소드
첫번째 요소를 삭제한 뒤 그 값을 반환한다.

그림과 같이 head = head.next를 통해 A가 아닌 B를 가리키게해서 첫번째 요소 A를 삭제할 수 있다. 하지만 경계조건을 고려해서 코드를 추가해야 한다.
Empty

헤드가 null을 가리키므로 head.next를 사용하면 NullPointerException이 발생한다. 이 상황에서는 null을 반환하면 된다.
Single element

요소가 여러개 있으면 tail 포인터를 신경쓸 필요없지만 리스트에 값이 하나라면 tail도 같이 고려해서 head와 tail 모두 null을 가리키게 하면 된다. currentSize == 1 혹은 head == tail을 통해 요소가 하나인 것을 확인할 수 있다.
public E removeFirst() {
if (head == null) return null;
E tmp = head.data;
if (head == tail) head = tail = null;
else head = head.next;
currentSize--;
return tmp;
}1-7. removeLast 메소드
마지막 요소를 삭제하고 그 값을 반환하는 메소드다.
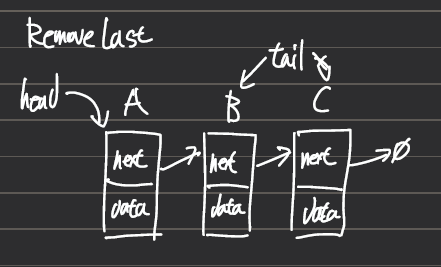
만약 위 그림과 같이 C를 지우고자 한다면 tail을 B를 가리키게하면 된다.
그런데 tail을 사용하면 마지막 요소인 C에 바로 접근할 수 있지만, tail을 이용해서 마지막 직전 노드인 B에 직접 접근할 수 있는 방법은 없다. 그래서 head부터 시작해서 currentSize까지 추적할 수도 있겠지만 2개의 tmp 포인터를 이용해서 현재 가리키는 노드가 마지막 요소인지 체크한다.

previous는 처음에 null을 가리키고, current는 head를 가리킨다. 그리고 previous를 current로 그리고 current를 current.next로 옮기면서 current가 마지막에 있는지 체크한다. curren == tail이거나, current.next == null 일 때, current가 마지막 노드를 가리킨다는 의미인데, 구현할 때는 current.next가 NullPointerException을 발생시킬 수 있으니 current==tail을 선호한다.
Empty, Single Element
removeFirst를 사용한다. removeFirst에서 boundary condition을 고려하므로 그대로 사용하면 된다.
public E removeLast() {
if (head==null) return null;
if (head==tail) return removeFirst();
Node<E> current = head, previous = null;
while (current != tail) {
previous = current;
current = current.next;
}
previous.next = null;
tail = previous;
currentSize--;
return current.data;
}1-8. remove와 find
removeFirst, removeLast와 다르게 특정 요소를 삭제하고 싶을 때 사용한다.

Comparable 인터페이스를 사용해서 제거하고 싶은 요소의 위치를 찾는다. removeLast와 마찬가지로 current와 previous 두개의 포인터를 사용해서 제거하고자 하는 노드와 바로 그 전 노드를 찾는다. 위 그림처럼 C를 제거하고자 한다면 previous인 B의 next가 D를 가리키게 하고 current인 C를 반환하면 된다.
Empty, Single element
Empty의 경우 null을 return하면 되고, Single element의 경우, removeFirst를 사용하면 된다.
Beginning, End
시작점이거나, 끝일 경우 removeFirst와 removeLast를 사용한다.
public E remove(E obj) {
Node<E> current = head, previous = null;
while (current != null) {
if (((Comparable<E>obj).compareTo(current.data)==0) {
if (current == head) return removeFirst();
if (current == tail) return removeLast();
currentSize--;
previous.next = current.next;
return current.data;
}
previous = current;
current = current.next;
}
return null;
}
코드를 통해 boundary condition에 대해 다시 한번 살펴본다.
1. List가 Empty일 때 어떻게 처리되는가?
head가 null일 때인데, while문이 애초에 실행이 안돼서 로직에서 Empty인지 체크해준다. 굳이 Empty인지 두번 체크할 필요가 없다.
2. 위 코드에서 if (current == tail) return removeLast();가 피요한 이유는 무엇인가?
위 코드가 없으면 remove()를 통해 요소를 삭제하면 tail이 이전 노드로 옮겨지지 않는다.
contains
public boolean contains(E obj)
obj를 입력받아서 리스트에 obj가 있다면 true, 없으면 false를 반환한다.
public E contains(E obj) {
Node<E> current = head;
while (current != null) {
if (((Comparable<E> obj).compareTo(current.data) == 0) {
return true;
}
current = current.next;
}
return false;
}
previous가 따로 필요 없고, remove에서 삭제하는 과정을 지우면 된다.
1-9. peek 메소드
peek는 LinkedList의 요소를 살펴보기 위해 사용한다. 앞의 추가, 제거가 아닌 내용을 읽는 함수이다.
peekFirst
public E peekFirst() {
if (head == null)
return null;
return head.data;
}
peekLast
tail을 사용하면 된다.
public E peekLast() {
if (tail==null)
return null;
return tail.data;
}
생각해보기
다음 두 코드의 차이는?
while (tmp.next != null)
while (tmp != null)
첫번째 코드는 tmp가 마지막 node에서 멈추게 된다. 그리고 두 번째 경우에는 마지막 node를 지나치게 된다. contains, remove에는 두번째 remove를 사용하지만 peek같은 경우는 굳이 previous와 같은 다른 포인터를 사용하지 않으므로 첫번째줄 코드처럼 마지막 노드에서 멈추는 것이 좋다.
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] 자바 힙 소개 및 구현 (0) | 2022.12.21 |
|---|---|
| [자료구조] 자바 해시 소개 및 구현 (0) | 2022.12.12 |
| [자료구조] 자바 반복자, 연결 리스트, 스택과 큐 (0) | 2022.12.05 |
| [자료구조] 객체지향프로그래밍 (0) | 2022.12.02 |
| [자료구조] 복잡성 : 자료구조 입문 (0) | 2022.11.24 |